Image classification refers to the task of assigning an input image one label from a fixed set of categories. This is one of the core problems in Computer Vision that, despite its simplicity, has a large variety of practical applications.
In this post we will learn how one of the most influential innovations in the field of computer vision (Convolutional Neural Network) can understand a natural image well-enough to solve image classification problem.
We will build an image classifiers from scratch, starting from JPEG images files on disk, without leveraging pre-trained weights or a pre-made keras application model, you can find all the code in my Github Repository
The Convolutional Classifier
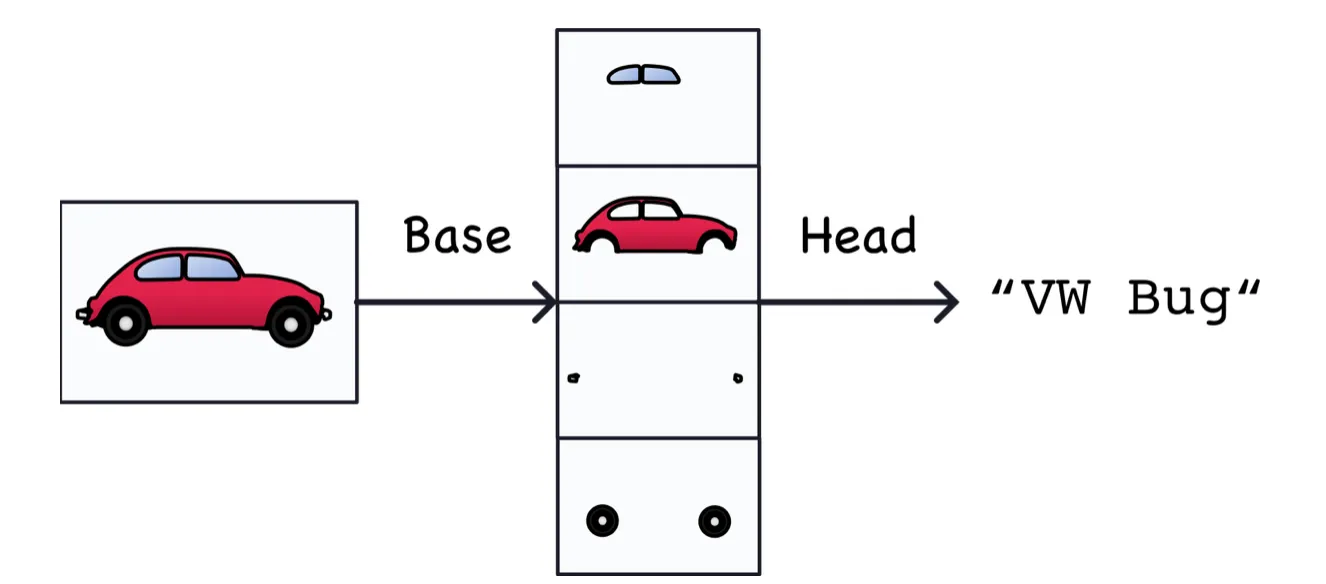
A Convolutional Network used for image classification has two parts: a convolutional base and a dense head.
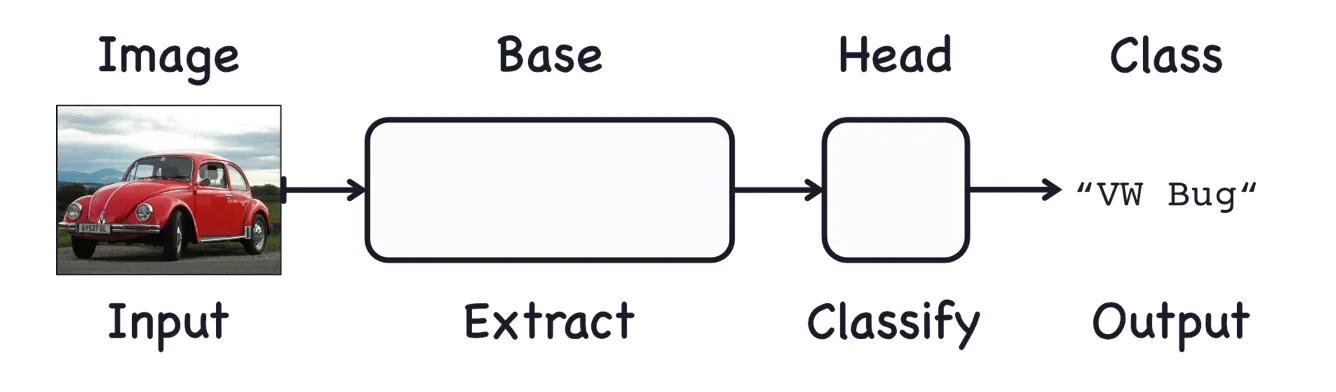
The base is used to extract the features from an image. It is formed primarily of layers performing the convolution operation, but often includes other kinds of layers as well.
feature could be a line, a color, a texture, a shape, a pattern or some complicated combination.
The head is used to determinate the class of the image. It is formed primarily of dense layers, but might include other layers like dropout.
Setup and Data preparation
Import TensorFlow and other libraries
import matplotlib.pyplot as pltimport numpy as np
import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersfrom tensorflow.keras.models import SequentialDownload the data
We are using a custom dataset created for this post to classificate Identification Cards, we will clone the dataset repository that contains 3 sub-directories inside training folder, one per class.
!git clone https://github.com/edinsonjim/ids-dataset.gitids-dataset├── readme.md├── test│ ├── 0001.jpeg│ ├── 0002.jpg│ ├── 0003.jpg│ ├── 0004.jpg│ └── 0005.png└── training ├── italy │ ├── 0000.jpg │ ├── 0001.jpg │ ├── 0003.jpg │ ├── 0004.jpg │ ├── 0005.jpg │ ├── 0006.jpg │ ├── 0007.jpg │ └── 0008.jpg ├── peru │ ├── 0001.jpg │ ├── 0002.jpg │ ├── 0003.jpg │ ├── 0004.jpg │ ├── 0005.jpg │ ├── 0006.jpg │ ├── 0007.jpg │ ├── 0008.jpg │ ├── 0009.jpg │ ├── 0010.jpg │ └── 0011.jpg └── spain ├── 0001.jpg ├── 0002.jpg ├── 0003.jpg ├── 0004.jpg ├── 0005.jpg └── 0006.jpgGenerate a dataset
After clone the repository, we can load the dataset using the helpful image_dataset_from_directory utility and create our training and validation dataset.
Let’s define some parameters for the loader.
WORK_DIR = "./ids-dataset/training"
IMAGE_HEIGHT = 180IMAGE_WIDTH = 180
IMAGE_SIZE = (IMAGE_HEIGHT, IMAGE_WIDTH)BATCH_SIZE = 10WORK_DIR: Path to training data.IMAGE_SIZE: Size to resize images to after they are read from disk.BATCH_SIZE: Number of samples that will be passed through to the network at one time.
Training dataset
Machine Learning algorithms require training data to achieve an objective. The algorithm will analyze this training dataset, classify the inputs and outputs. These operations allow the model to learn the relationship between the data.
train_ds = tf.keras.preprocessing.image_dataset_from_directory( WORK_DIR, validation_split=0.2, subset="training", seed=1337, image_size=IMAGE_SIZE, batch_size=BATCH_SIZE,)Found 25 files belonging to 3 classes.Using 20 files for training.Validation dataset
A trained algorithm will essentially memorize all of the inputs and outputs in a training dataset, this becomes a problem when it need to consider data from other sources.
Here is where validation data is useful. Validation data provides an initial check that the model can return useful predictions in a real-world setting.
val_ds = tf.keras.preprocessing.image_dataset_from_directory( WORK_DIR, validation_split=0.2, subset="validation", seed=1337, image_size=IMAGE_SIZE, batch_size=BATCH_SIZE,)Found 25 files belonging to 3 classes.Using 5 files for validation.It’s a good practice to use a validation split when developing your model. Let’s use 80% of the images for training, and 20% for validation.
We can find the class names in the class_names attribute on these datasets, that correspond to the directory names in alphabetical order.
class_names = train_ds.class_namesprint(class_names)['italy', 'peru', 'spain']Visualize the data
Let’s visualize the first images in the training dataset.
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1): for i in range(9): ax = plt.subplot(3, 3, i + 1) plt.imshow(images[i].numpy().astype("uint8")) plt.title(class_names[labels[i]]) plt.axis("off")
Configure the dataset for performance
Let’s make sure to use buffered prefetching so we can yield data from disk without having I/O becoming blocking. These are two important methods you should use when loading data.
Dataset.cache() keeps the images in memory after they’re loaded off disk during the first each. This will ensure the dataset does not become a bottleneck while training your model. If your dataset is too large to fit into memory, you can also use this method to create a performant on-disk cache.
Dataset.prefetch() overlaps data preprocessing and model execution while training.
If you are interested, you can learn more about how to cache data in the data performance guide.
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)Data augmentation
When you don’t have a large image dataset, it’s a good practice to artificially introduce sample diversity by applying random yet realistic transformations to the training images, such as random horizontal flipping or small random rotations. This helps expose the model to different aspects of the training data while slowing down overfitting.
COLOR_CHANNELS = 3 # 3 channels (RGB)
data_augmentation = keras.Sequential( [ layers.experimental.preprocessing.RandomFlip("horizontal", input_shape=(IMAGE_HEIGHT, IMAGE_WIDTH, COLOR_CHANNELS)), layers.experimental.preprocessing.RandomRotation(0.01), layers.experimental.preprocessing.RandomZoom(0.01) ])input_shape: Initial tensor that we send to the first hidden layer. This tensor should have the same shape as our training data.
Let’s visualize what the augmented samples looks like, by applying data_augmentation repeatedly to the first images in the dataset.
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1): for i in range(9): augmented_images = data_augmentation(images) ax = plt.subplot(3, 3, i + 1) plt.imshow(augmented_images[0].numpy().astype("uint8")) plt.axis("off")
Standardizing the data
Our image are already in a standard size (180x180), as they are being yielded as contiguos float32 batches by our dataset. However, their RGB channel values are in the [0, 255] range. This is not ideal for a neural network; in general you should seek to make your input values small. Here, we will standardize values to be in the [0, 1] by using a Rescaling layer at the start of our model.
normalization_layer = layers.experimental.preprocessing.Rescaling(1./255)Build a model
Now we’ll define a small model. See how our model consist of six blocks of Conv2D and MaxPool2D layers(the base) followed by a head of Dense layers.

Notice in this definition how the number of filters doubled block by block: 8, 16, …, 512. This is a common pattern. Since the
MaxPool2Dlayer is reducing the size of the feature maps, we can afford to increase the quantity if we wish.
We have three ways to create Keras models, for this post we use the Sequential model, wich is limited to single-input and single-output layer stacks. To know other methods, you can visit Keras Models API.
num_classes = len(class_names)
model = Sequential([ # preprocessing data_augmentation, normalization_layer,
# first convolutional block layers.Conv2D(filters=8, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(),
# second convolutional block layers.Conv2D(filters=16, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(),
# third convolutional block layers.Conv2D(filters=32, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(),
# fourth convolutional block layers.Conv2D(filters=64, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(),
# fifth convolutional block layers.Conv2D(filters=128, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(),
# sixth convolutional block layers.Conv2D(filters=256, kernel_size=3, padding='same', activation='relu'), layers.MaxPool2D(), layers.Dropout(rate=0.2), # apply 20% dropout to the next layer to prevent overfitting
# classifier Head layers.Flatten(), layers.Dense(units=512, activation='relu'), layers.Dense(units=num_classes)])Note that:
- We start the model with the
data_augmentationpreprocesor, followed by anormalizationlayer previously detailed. - We include a
Dropoutlayer before the final classification layer, used to simulate different network architectures by randomly removing nodes during training, helping to prevent overfitting.
Compile the model
Choose the optimizers.Adam optimizer and losses.SparseCategoricalCrossentropy loss function. To view training and validation accuracy for each training epoch, pass the metrics argument.
model.compile( optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=["accuracy"],)optimizers.Adam: Is a stochastic gradient descent method that is based on adaptive estimation of first-order and second-order moments. Used to perform optimization and is one of the best optimizer at preset. You can read this paper for more details.losses.SparseCategoricalCrossentropy: Use this function when there are two or more label classes. We expect labels to be provided as integers.
Model summary
If you want to view all the layers of the network, you can use the model’s summary method.
model.summary()Model: "sequential_95"_________________________________________________________________Layer (type) Output Shape Param #=================================================================sequential_90 (Sequential) (None, 180, 180, 3) 0_________________________________________________________________rescaling_8 (Rescaling) (None, 180, 180, 3) 0_________________________________________________________________conv2d_352 (Conv2D) (None, 180, 180, 8) 224_________________________________________________________________max_pooling2d_400 (MaxPoolin (None, 90, 90, 8) 0_________________________________________________________________conv2d_353 (Conv2D) (None, 90, 90, 16) 1168_________________________________________________________________max_pooling2d_401 (MaxPoolin (None, 45, 45, 16) 0_________________________________________________________________conv2d_354 (Conv2D) (None, 45, 45, 32) 4640_________________________________________________________________max_pooling2d_402 (MaxPoolin (None, 22, 22, 32) 0_________________________________________________________________conv2d_355 (Conv2D) (None, 22, 22, 64) 18496_________________________________________________________________max_pooling2d_403 (MaxPoolin (None, 11, 11, 64) 0_________________________________________________________________conv2d_356 (Conv2D) (None, 11, 11, 128) 73856_________________________________________________________________max_pooling2d_404 (MaxPoolin (None, 5, 5, 128) 0_________________________________________________________________conv2d_357 (Conv2D) (None, 5, 5, 256) 295168_________________________________________________________________max_pooling2d_405 (MaxPoolin (None, 2, 2, 256) 0_________________________________________________________________dropout_68 (Dropout) (None, 2, 2, 256) 0_________________________________________________________________flatten_87 (Flatten) (None, 1024) 0_________________________________________________________________dense_177 (Dense) (None, 512) 524800_________________________________________________________________dense_178 (Dense) (None, 3) 1539=================================================================Total params: 919,891Trainable params: 919,891Non-trainable params: 0Train the model
epochs = 50
history = model.fit( train_ds, epochs=epochs, validation_data=val_ds,)An epoch is one pass through an entire dataset. This can be in random order.
Visualize training results
The keras fit() method returns an object containing the training history, including the value of metrics at the end of each epoch.
Let’s plot the metrics(loss and accuracy) from the training and validation sets.
# training and validation accuracyacc = history.history['accuracy']val_acc = history.history['val_accuracy']
# training and validation lossloss = history.history['loss']val_loss = history.history['val_loss']
epochs_range = range(epochs)
# plot settings for Accuracyplt.figure(figsize=(8, 8))plt.subplot(1, 2, 1)plt.plot(epochs_range, acc, label="Training Accuracy")plt.plot(epochs_range, val_acc, label="Validation Accuracy")plt.legend(loc="lowe right")plt.title("Training and Validation Accuracy")
# plot settings for Lossplt.subplot(1, 2, 2)plt.plot(epochs_range, loss, label="Training Loss")plt.plot(epochs_range, val_loss, label="Validation Loss")plt.legend(loc="upper right")plt.title("Training and Validation Loss")plt.show()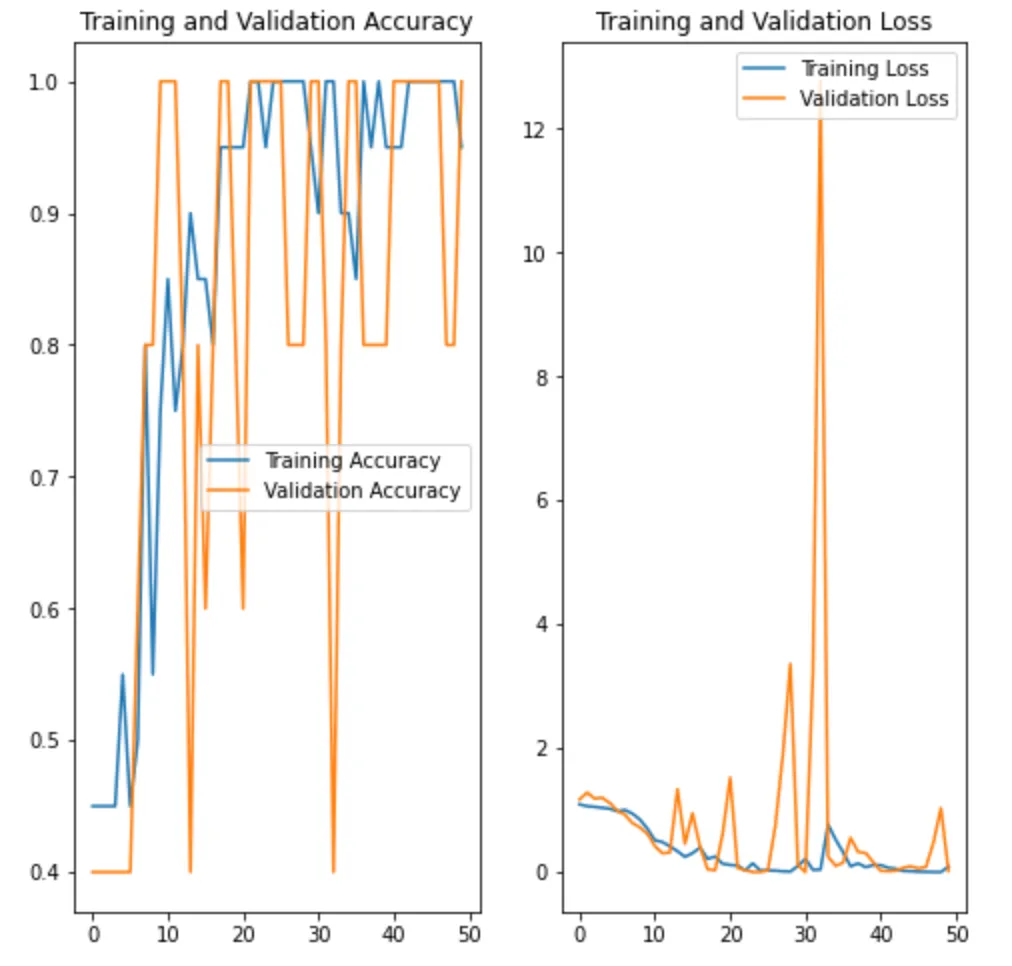
Predict on new data
Finally, let’s use our model to classify an image that wasn’t included in the training or validation sets, but first we create a show_and_predict helper method to download, prepare and show the model predictions.
def show_and_predict(img_path): """ Download, prepare and show model predictions """ img = keras.preprocessing.image.load_img( img_path, target_size=IMAGE_SIZE )
img_array = keras.preprocessing.image.img_to_array(img) img_expanded = tf.expand_dims(img_array, 0) # create a batch
predictions = model.predict(img_expanded) score = tf.nn.softmax(predictions[0])
plt.imshow(img_array/255) plt.axis("off")
class_name_predicted = class_names[np.argmax(score)] score_predicted = 100 * np.max(score)
print( f"This image is most likely a document from {class_name_predicted} with a {score_predicted:.2f} percent confidence." )Now, we can use our helper method and classify new images.
show_and_predict('./ids-dataset/test/0001.jpeg')
show_and_predict('./ids-dataset/test/0005.png')